Example Gallery¶
In this section, we present illustrative examples for importing files serialized with the CSD model, using the csdmpy package. Because the CSD model allows multi-dimensional datasets with multiple dependent variables, we use a shorthand notation of \(d\mathrm{D}\{p\}\) to indicate that a dataset has a \(p\)-component dependent variable defined on a \(d\)-dimensional coordinate grid. In the case of correlated datasets, the number of components in each dependent variable is given as a list within the curly braces, i.e., \(d\mathrm{D}\{p_0, p_1, p_2, ...\}\).
Scalar, 1D{1} datasets¶
The 1D{1} datasets are one dimensional, \(d=1\), with one single-component, \(p=1\), dependent variable. These datasets are the most common, and we, therefore, provide a few examples from various fields of science.
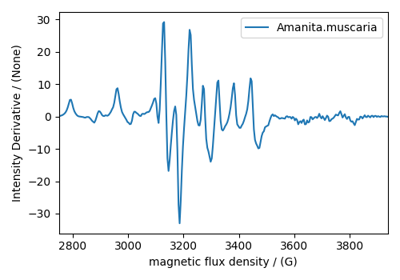
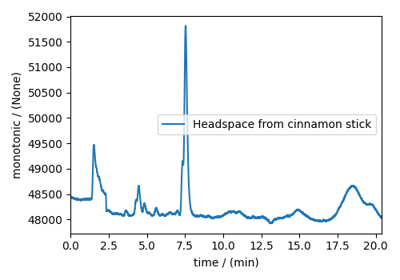
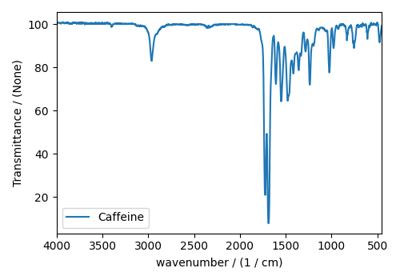
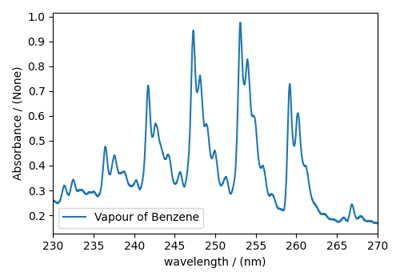
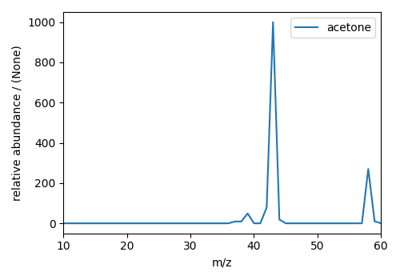
Fourier Transform Infrared Spectroscopy (FTIR) dataset
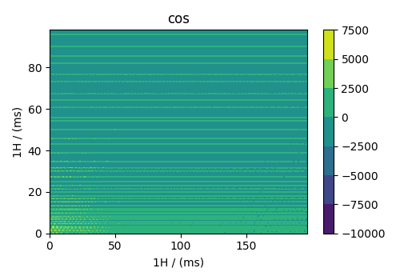
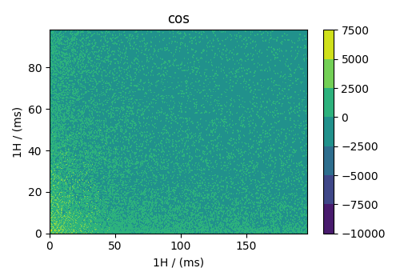
Scalar, 2D{1} datasets¶
The 2D{1} datasets are two dimensional, \(d=2\), with one single-component dependent variable, \(p=1\). Following are some 2D{1} example datasets from various scientific fields expressed in CSDM format.
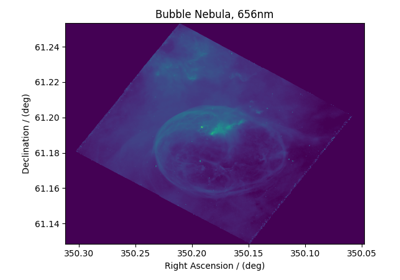
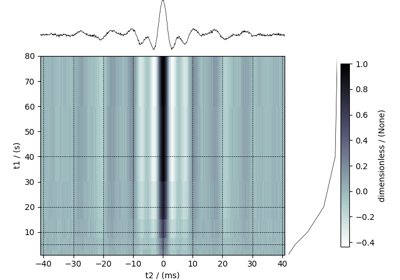
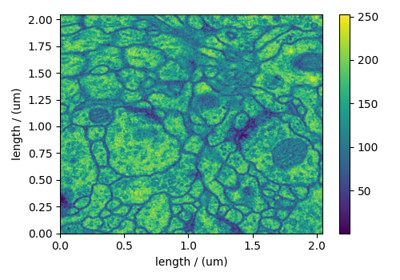
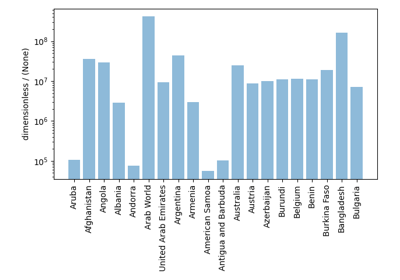
Vector datasets¶
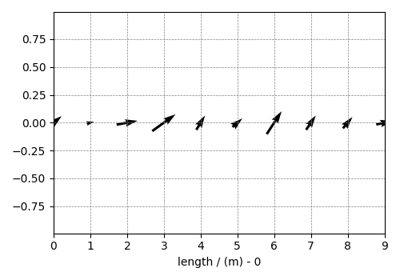
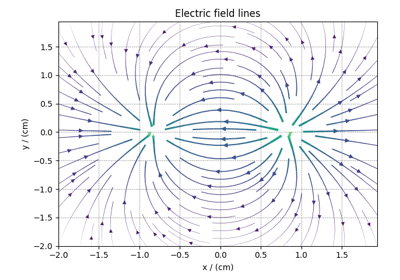
Tensor datasets¶
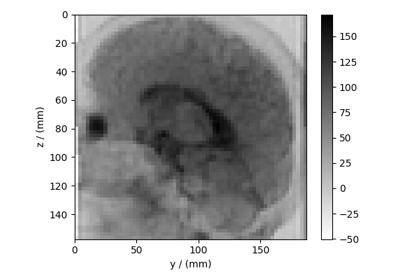
Pixel datasets¶

Correlated datasets¶
The Core Scientific Dataset Model (CSDM) supports multiple dependent variables that share the same d-dimensional coordinate grid, where \(d>=0\). We call the dependent variables from these datasets as correlated datasets. Following are a few examples of the correlated dataset.
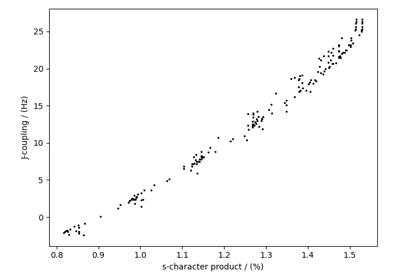
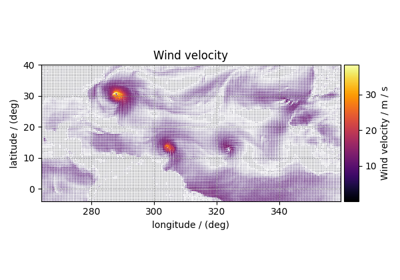
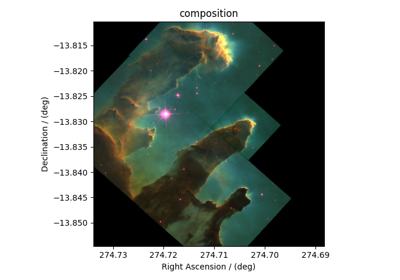
Astronomy, 2D{1,1,1} dataset (Creating image composition)